A quick write up of an incident yesterday that bit us and caused 2 rollbacks of our live UK website, and I thought I'd write it up as I think it highlights a number of things around the organisation and its culture, and was ultimately a 'good day'.
Our bingo website release pipeline is pretty streamlined, and we generally release "relatively regularly" (2-3 times per week). I use the air quotes, as 2-3 times a week is nowhere near a short enough feedback loop if we're attempting to amplify the feedback loop, but we are improving that all the time (the pipeline would happily push all changes to live multiple times per day, but there are more considerations there - a topic for another post).
The key failing up front: It had been 8 days since we released (for no good reason), and our release yesterday morning seemed to go great - all unit tests passed, integration - tick, e2e - tick, smoke tests - tick. We'd manually checked our inactive stack (we do blue-green deployment), and all was good to go. We switched the customers over to the new release, and all was great.
Then it wasn't... About 10minutes after the release we started to get some exceptions on one of our dashboards:

All of which were loudly looking like database connectivity issues.
Which was quickly followed in hipchat by notifications from our customer service staff:

Cultural Win #1
We're not what you would call a DevOps setup - we do have separate development and operations teams, and in the past, we have struggled in the same way that a lot of organisations that separate these functions do - we're on the same journey, but looking out of different windows. It's the usual issues that have been blogged about by others at length - infrastructure blaming developers for setting the world on fire, developers blaming infrastructure for moving slower than they want - both wanting to achieve exactly the same outcome for the business, neither one of them realising it. You've seen it play out in many organisations I'm sure.
We've spent a lot of time as an organisation and as teams trying to improve upon our communication, respect, and overall culture, and it played out brilliantly in this - we all gathered together, talked about the issues, investigated quickly and came up with some cracking approaches on diagnosis that helped us rule out both any infrastructure changes and database changes really quickly. There was no blame, there was no 'us and them', there was just 'let's get this fixed, together' with a focus entirely on the customer.
For those organisations that have evolved their practices into either a more DevOps approach, or have gone through the cultural change and have evolved a shared why and a shared journey, this may seem simple, but even 6 months ago this would have been a situation that generated far more friction and silo'd mentality.
Although we were still having the live issues, we knew that rolling back the site and investigating together was then the right thing to do, and there was shared ownership.
Root Cause, and Cultural Win #2
As the feedback loop wasn't great: 8 days of regular code commits across two teams, a number of active projects in development, and a number of new pathways (albeit feature toggled off), so getting to root cause was a daunting task.
We peer review every single merge to our releasable branch, so if it was code, it was likely to be something very subtle. It turned out there had been 193 commits and 231 files changed, so it felt like it was going to be a needle in a haystack.
We got lucky - while I was reviewing a piece of code, I saw a unity resolution setup like this:
container.RegisterType<ICoreThingyService, CoreThingyService>(new ContainerControlledLifetimeManager());
Oh, snap. Our services almost all register as PerResolveLifetimeManager, and this one had been new'd up as a singleton. This had dependencies against data connections, and although those data connection dependencies were per resolve, it would never matter as we had one copy of the above for the lifetime of the application, so the connections were getting held onto (and worse, during connection pooling saturation, disposed of without getting re-setup). Suddenly it all became clear on why the core issues were all database related.
We have two teams working on this codebase, and again, it's an indicator of the strength of our interactions and culture that it became then a blameless discussion, an agreement on this as the root cause, and, as soon as the fix was put in place, a shared review of the fix to quickly get it available for testing.
It's a loooong time since I've been bitten by a singleton in a codebase, but I would guess it won't be the last in my career. They're awesome, except in the many, many situations where they absolutely are not!
Continual Improvement - Next Steps
I've worked at tombola now for a little over 8 years, and it brings great comfort that the organisation is where it is now. It's always been a generally good place to work culturally, but there's definitely a strong shift over the past year or so into something that is far more collaborative, more respectful, and with a greater understanding of the 'why'.
Some steps I've identified from this one issue:
- Shorten and amplify the feedback loop - although our feedback loop in terms of dashboarding, alerting, etc. is pretty good, if we had been releasing more regularly as a matter of course, we would have seen this within a very short space of time after it was introduced, and then diagnosis would have been so much easier and quicker.
- Tie in simple load testing to releases - once I'd integrated the fix into our release branch (which then went through all of our testing listed above, and automatically deployed through our dev and UAT environments), I load tested it with apache bench to validate that I could not replicate the problem.
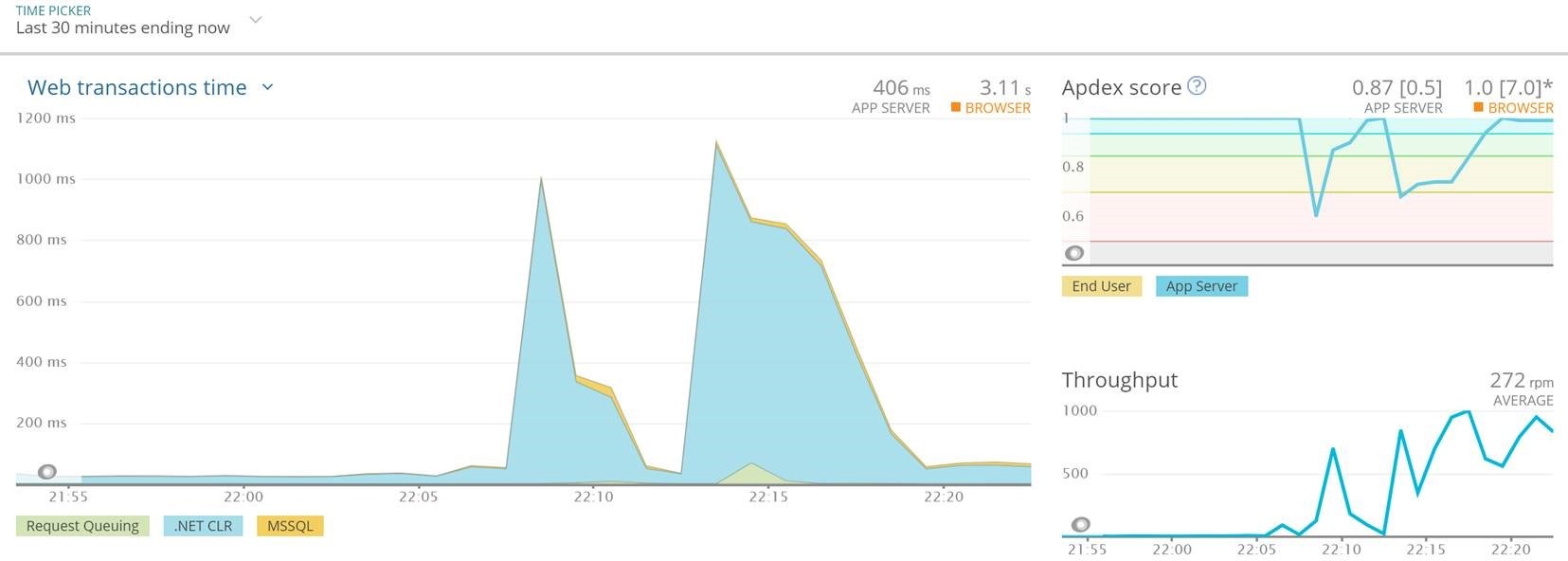 Although I could hammer the response times (the server I load tested isn't load balanced and is far smaller than our production boxes), I was hitting it with enough load to saturated and replicate the problem we'd seen in live and we had zero exceptions raised from the testing.I will ensure that we tie this into our release cycle at some point so that we routinely perform automated load testing on our deploying code, and alert the pipeline if there are any issues.
Although I could hammer the response times (the server I load tested isn't load balanced and is far smaller than our production boxes), I was hitting it with enough load to saturated and replicate the problem we'd seen in live and we had zero exceptions raised from the testing.I will ensure that we tie this into our release cycle at some point so that we routinely perform automated load testing on our deploying code, and alert the pipeline if there are any issues. - Cultural - I think tombola are on a great path here already, but it feels great to be part of that cultural shift towards more respectful, shared collaboration. I'll endeavour to live that 'why'.
